
3.2: Data and information
- Page ID
- 22994

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)What constitutes data and information is a fundamental question that attracts much interest and invites numerous definitions. This chapter introduces definitions suitable to the symbolic representations discussed in the previous part, towards a transparent basis for information management.
Theories and definitions
There is nothing more practical than a good theory: it supplies the definitions people need in order to agree what to do, how and why; it explains the world, providing new perspectives from which we can view and understand it; it establishes targets for researchers keen to improve or refute the theory and so advance science and knowledge. In our case, there is a clear need for good, transparent and operational definitions. Terms like ‘information’ and ‘data’ are used too loosely, interchangeably and variably to remove ambiguities in information processing and management. Management, computing and related disciplines abound with rather too easy, relational definitions of data, information, knowledge, strategy etc., e.g. that data interpreted become information, information understood turns into knowledge and so forth. Such definitions tend to underestimate the complexity of cognitive processes and are therefore not to be trusted. Even methodically sound studies, involving large numbers of leading scholars, can do little to elucidate the meaning and usage of these terms.[1] Arguably, asking for succinct, all-encompassing definitions abstracts the context from which the definitions derive and renders them too axiomatic or too vague.
A theory that resolves these problems cannot draw from the AECO domains only. It needs a firm foundation in general theories of information, especially those that take the potential and peculiarities of digital means into account. Thankfully, there are enough candidates for this.
Syntactic, semantic and pragmatic theories
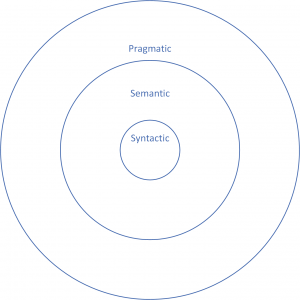
When one thinks of information theory in a computing context, Shannon’s MTC springs to mind.[2] The MTC is indeed foundational and preeminent among formal theories of information. It addresses what has been visualized as the innermost circle in information theory (Figure 1):[3] the syntactic core of information, dealing with the structure and basic, essential aspects of information, including matters of probability, transmission flows and capacities of communication facilities — the subjects of the technical side of information theory.
The outermost circle in the same visualization is occupied by pragmatics: real-life usage of meaningful information. IM theories (discussed in the next chapter) populate this circle, providing a general operational framework for supporting and controlling information quality and flow. To apply this framework, one requires pragmatic constraints and priorities from application areas. For example, a notary and a facility manager have different interests with regard to the same building information.
Between the syntactic and the pragmatic lies the intermediate circle of semantics, which deals with how meaning is added to the syntactical components of information before they are utilized in real life. As syntactic approaches are of limited help with the content of information and its interpretation, establishing a basis for IM requires that we turn to semantic theories of information.
Arguably the most appealing of these is by Luciano Floridi, who is credited with establishing the subject of philosophy of information. The value of his theory goes beyond his position as a modern authority on the subject. The central role of semantics in his work is an essential contribution to the development of much-needed theoretical principles in a world inundated with rapidly changing digital technologies. In our case, it promises a clear and coherent basis for understanding AECO information and establishing parsimonious structures that link different kinds of information and data. These structures simplify IM in a meaningful and relevant manner: they allow us to shift attention from how one should manage information (the technical and operational sides) to which information and why.
In this book, we focus on data, information and their relation in the operational context of digital building representations. Utilization of information and resulting benefits for individuals, enterprises, disciplines or societies are subjects that require extensive analyses well beyond the scope of the present book. Information certainly contributes to achieving these benefits; in many cases it may even be a prerequisite but seldom suffices by itself. Rather than making unfounded claims about knowledge and performance, we focus on more modest goals concerning IM: understanding building information, its quality and flows, and organizing them in ways that may help AECO take informed decisions, in the hope that informed also means better.
A semantic theory for building information
Data and information instances
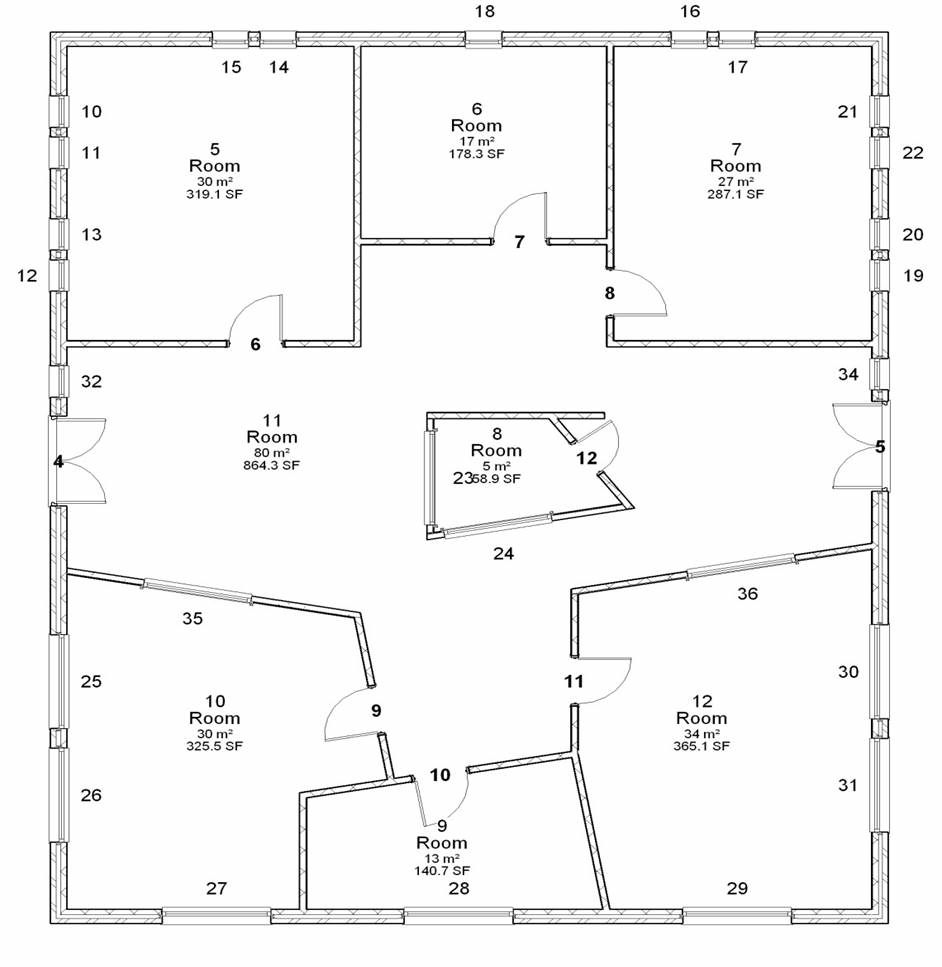
A fundamental definition in Floridi’s theory[4] concerns the relation between data and information: an instance of information consists of one or more data which are well-formed and meaningful. Data are defined as lacks of uniformity in what we perceive at a given moment or between different states of a percept or between two symbols in a percept. For example, if a coffee stain appears on a floor plan drawing on paper (Figure 3), this is certainly a lack of uniformity with the previous, pristine state of the drawing (Figure 2) but it is neither well-formed nor meaningful within the context of architectural representations. It tells us nothing about the representation or the represented design, except that someone has been rather careless with the drawing (the physical carrier of the representation).
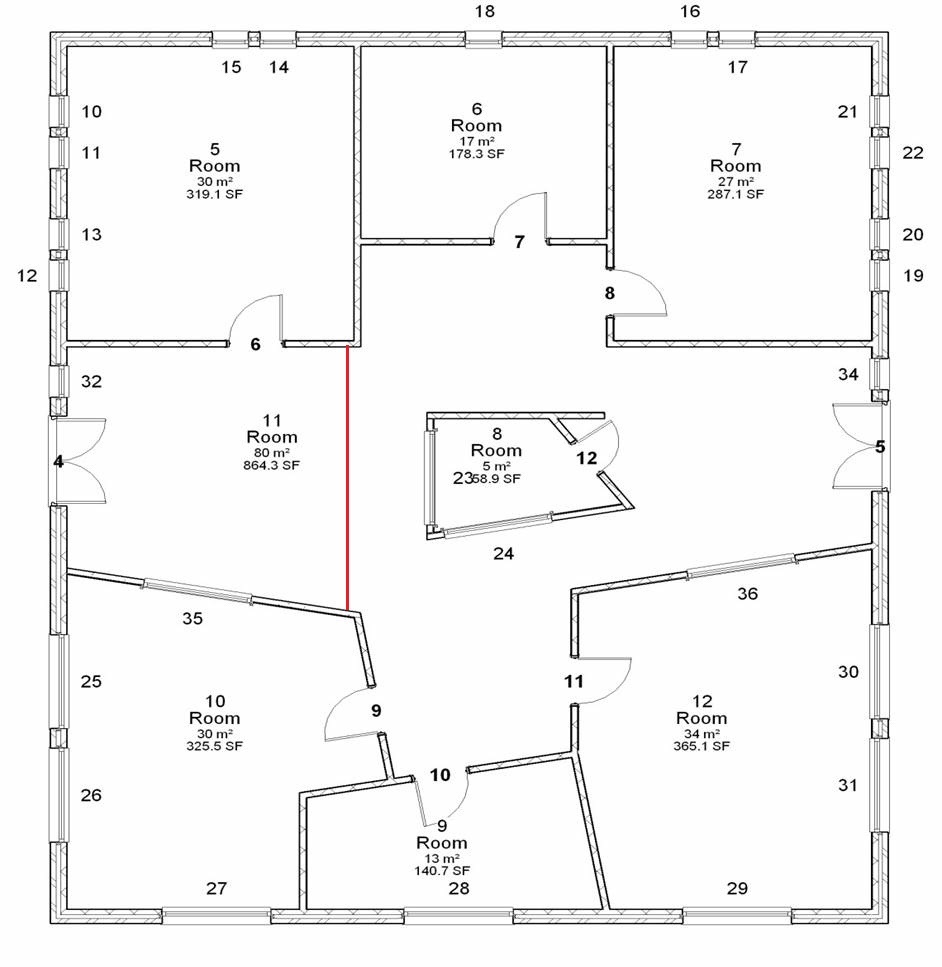
On the other hand, if the lack of uniformity between the two states is a new straight line segment across a room in a floor plan (Figure 4), this is both well-formed (as a line in a line drawing) and meaningful (indicating a change in the design, possibly that the room has now a split-level floor).
Data and information types
The typology of data is a key component in Floridi’s approach. Data can be:
- Primary, like the name and birth date of a person in a database, or the light emitted by an indicator lamp to show that a radio receiver is on.
- Anti–data,[5] i.e. the absence of primary data, like the failure of an indicator lamp to emit light or silence following having turned the radio on. Anti-data are informative: they tell us that e.g. the radio or the indicator lamp are defective.
- Derivative: data produced by other, typically primary data, which can therefore serve as indirect indications of the primary ones, such as a series of transactions with a particular credit card as an indication of the trail of its owner.
- Operational: data about the operations of the whole system, like a lamp that indicates whether other indicator lamps are malfunctioning.
- Metadata: indications about the nature of the information system, like the geographic coordinates that tell where a digital photograph has been taken.
These types also apply to information instances, depending on the type of data they contain: an information instance containing metadata is meta-information.
In the context of analogue building representations like floor plans (Figure 5), lines denoting building elements are primary data. They describe the shape of these elements, their position and the materials they comprise.
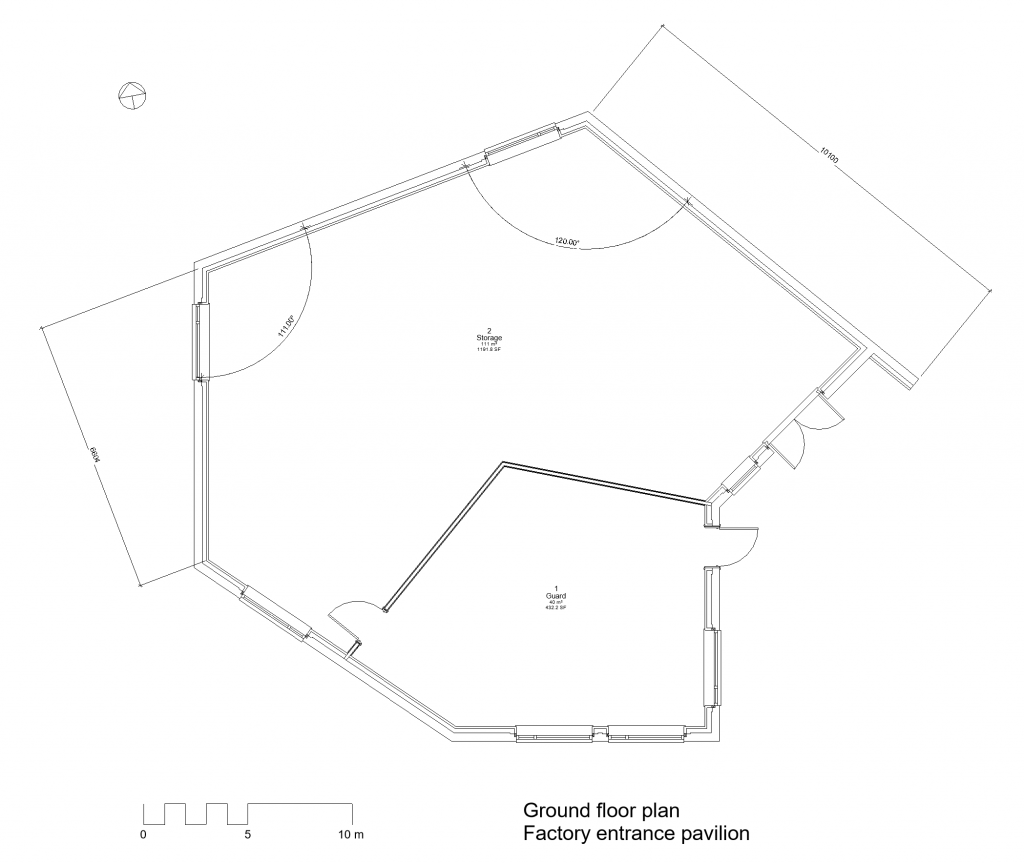
In addition to geometric primary data, an analogue floor plan may contain alphanumeric primary data, such as labels indicating the function of a room or dimension lines (Figure 6). A basic principle in hand drawing is that such explicitly specified dimensions take precedence over measurements in the drawing because amending the dimensions is easier than having to redraw the building elements.
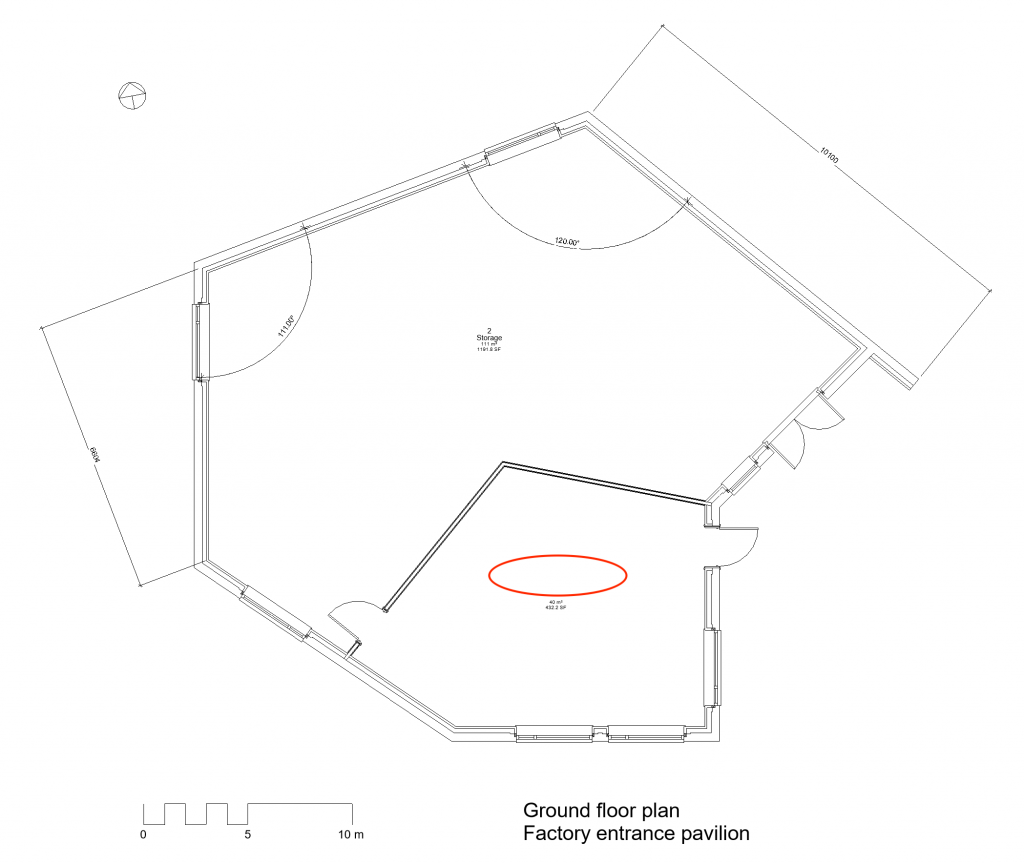
Anti-data are rather tricky to identify in the typically abstract and elliptical analogue building representations. Quite often it is hard to know if something is missing. One should therefore consider absence as anti-data chiefly when absence runs contrary to expectation and is therefore directly informative: a door missing from the perimeter of a room indicates either a design mistake or that the room is inaccessible (e.g. a shaft). Similarly, a missing room label indicates either that the room has no specific function or that the drawer has forgotten to include it in the floor plan (Figure 7).
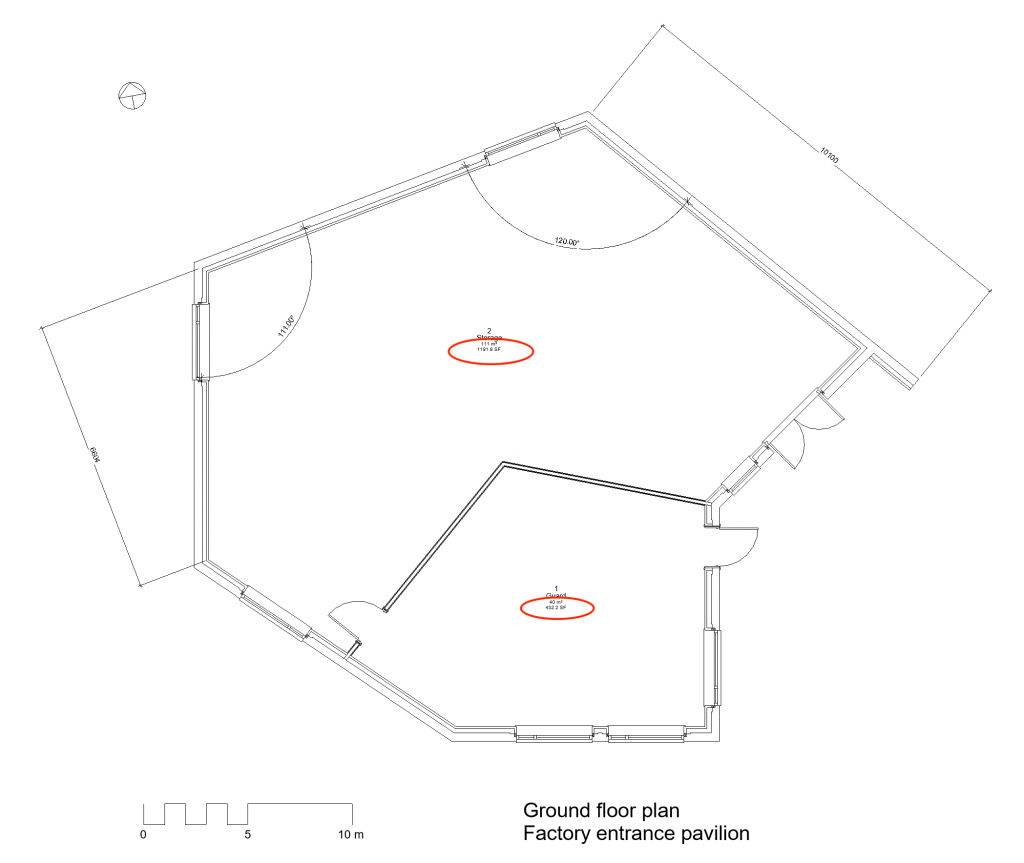
Derivative data in building representations generally refer to the abundance of measurements, tables and other data produced from primary data in the representation, such as floor area labels in a floor plan (Figure 8). One can recognize derivative data from the fact that they can be omitted from the representation without reducing its completeness or specificity: derivative data like the area of a room can be easily reproduced when necessary from primary data (the room dimensions). An important point is that one should always keep in mind the conventions of analogue representations, like the precedence of dimension lines over measurement in the drawing, which turns the former into primary data.
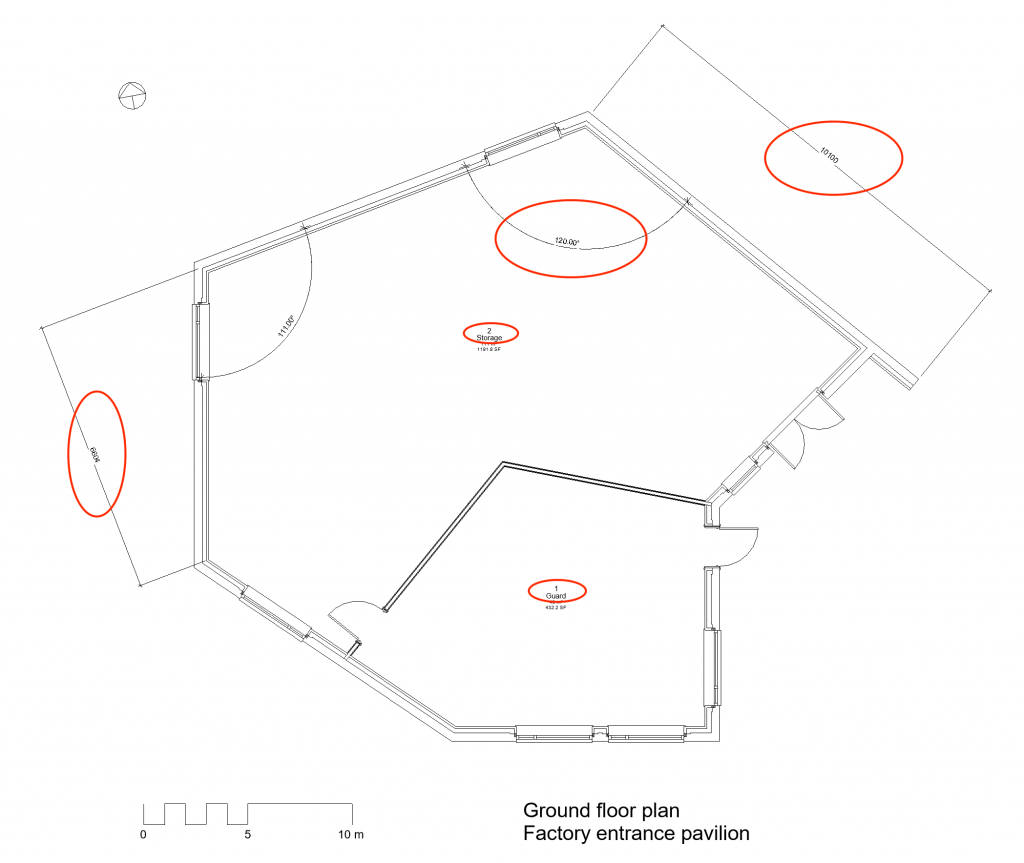
Operational data reveal the structure of the building representation and explain how data should be interpreted. Examples include graphic scale bars and north arrows, which indicate respectively the true size of units measured in the representation and the true orientation of shapes in the design (Figure 9).
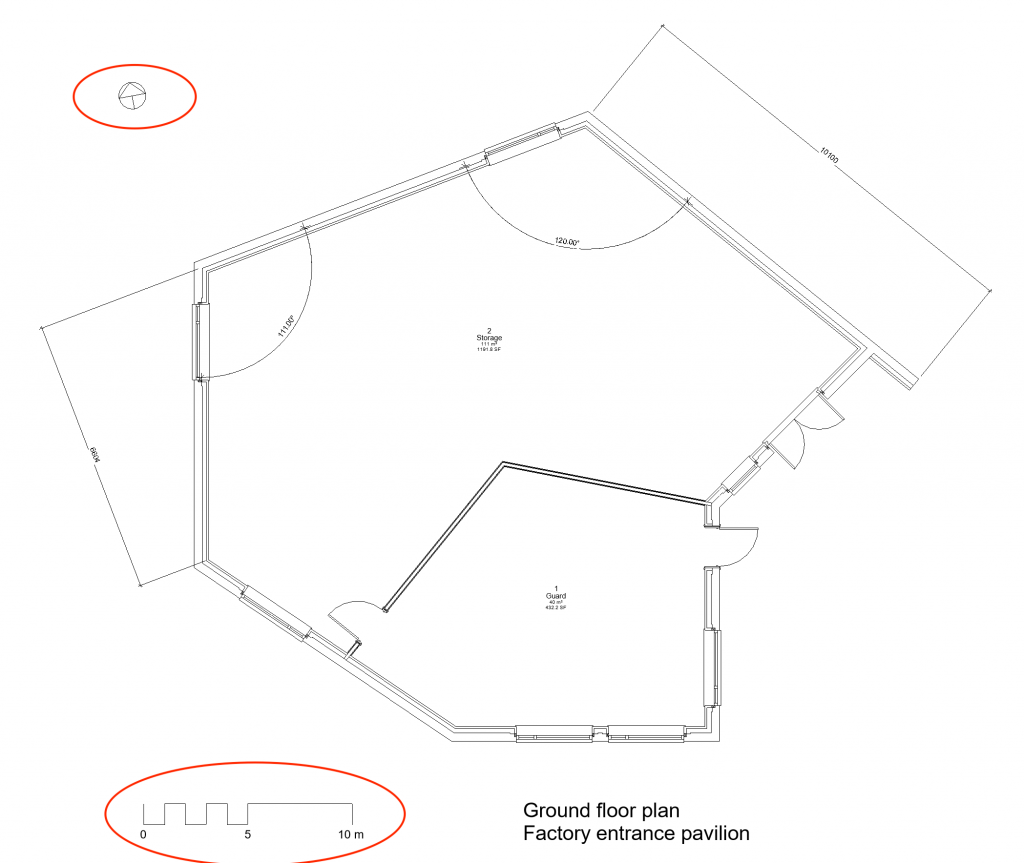
Finally, metadata describe the nature of the representation, such as the projection type and the design project or building, e.g. labels like ‘floor plan’ (Figure 10).
BIM, information and data
Data types in BIM
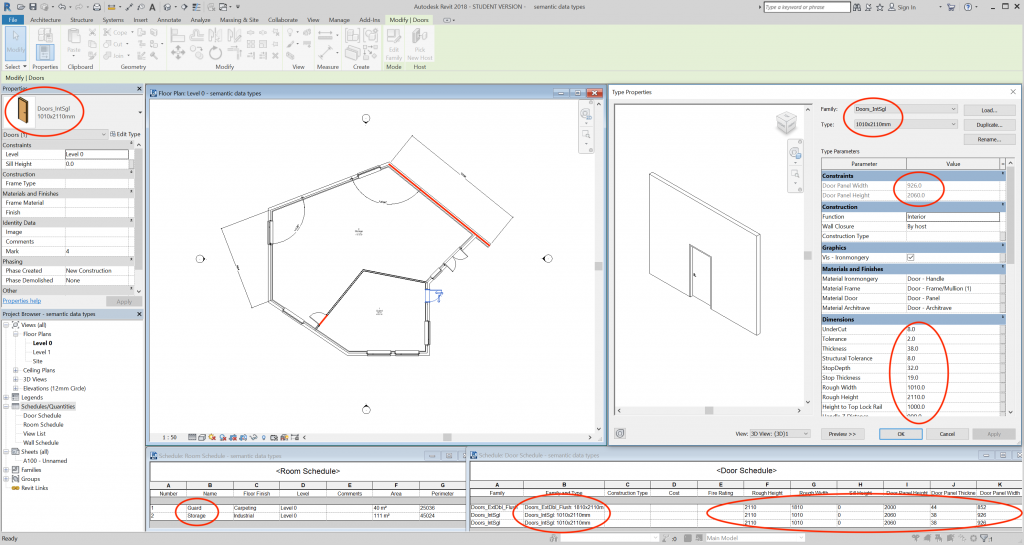
As we have seen in previous chapters, computerization does not just reproduce analogue building representations. Digital representations may mimic their analogue counterparts in appearance but can be quite different in structure. This becomes evident when we examine the data types they contain. Looking at a BIM editor on a computer screen, one cannot help observing a striking shift in primary and derivative data (Figure 11 & 12): most graphic elements in views like floor plans are derived from properties of symbols. In contrast to analogue drawings, dimension lines and their values in BIM are derivative, pure annotations like floor area calculations in a space. This is understandable: the ease with which one can modify a digital representation renders analogue practices of refraining from applying changes to a drawing meaningless.
Less intuitive is that even the lines denoting the various materials of a building element are derivative, determined by the type of the symbol: if the type of a wall changes, then all these graphic elements change accordingly. In analogue representations the opposite applies: we infer the wall type from the graphic elements that describe it in terms of layers of materials and other components.
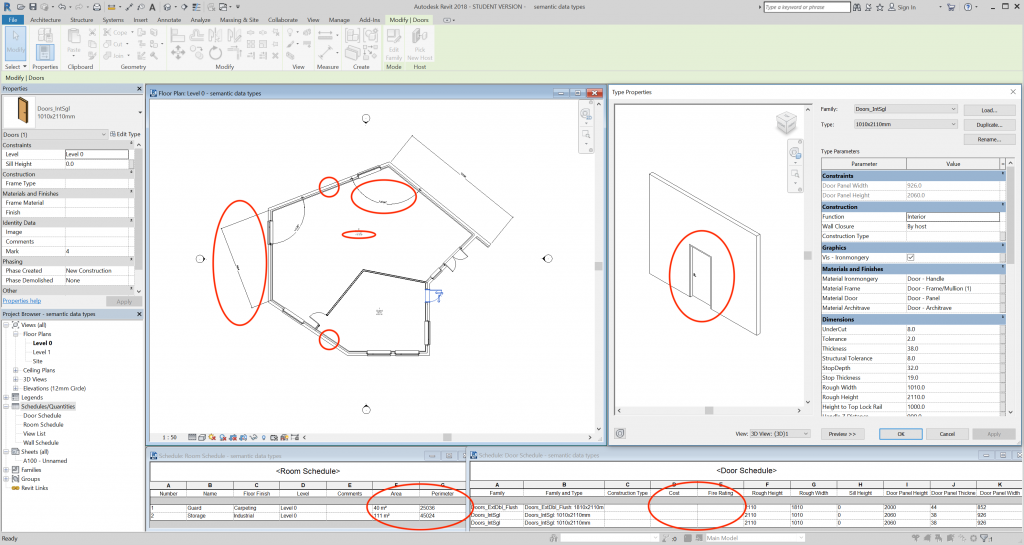
The main exception to this shift is the geometry of symbols. As described in the previous chapter, when one enters e.g. a wall in BIM, the usual workflow is to first choose the type of the wall and then draw its axis in a geometric view like a floor plan. Similarly, modifications to the location or shape of the wall are made by changing the same axis, while other properties, like layer composition and material properties of each layer, can only be changed in the definition of the wall type. One can also change the axis by typing new coordinates in some window but in most BIM editors the usual procedure is interactive modification of the drawn axis with a pointer device like a mouse. Consequently, primary data appear dispersed over a number of views and windows, including ones that chiefly contain derivative data.
One should not be confused by the possibilities offered by computer programs, especially for the modification of entities in a model. The interfaces of these programs are rich with facilities for interacting with shapes and values. It seems as if programmers have taken the trouble to allow users to utilize practically everything for this purpose. For example, one may be able to change the length of a wall by typing a new value for its dimension line, i.e. via derivative data. Such redundancy of entry points is highly prized in human-computer interaction but may be confusing for IM, as it tends to obscure the type of data and the location where each type can be found. To reduce confusion and hence the risk of mistakes and misunderstandings, one should consider the character of each view or window and how necessary it is for defining an entity in a model. A schedule, for example, is chiefly meant for displaying derivative data, such as area or volume calculations, but may also contain primary data for reasons of overview, transparency or legibility. Most schedules are not necessary for entering entities in a model, in contrast to a window containing the properties of a symbol, from where one chooses the type of the entity to be entered. In managing the primary data of a symbol one should therefore focus on the property window and its contents.
Computer interfaces also include more operational data, through which users can interact with the software. Part of this interaction concerns how other data are processed, including in terms of appearance, as with the scale and resolution settings in drawing views mentioned in the previous chapter (Figure 13).
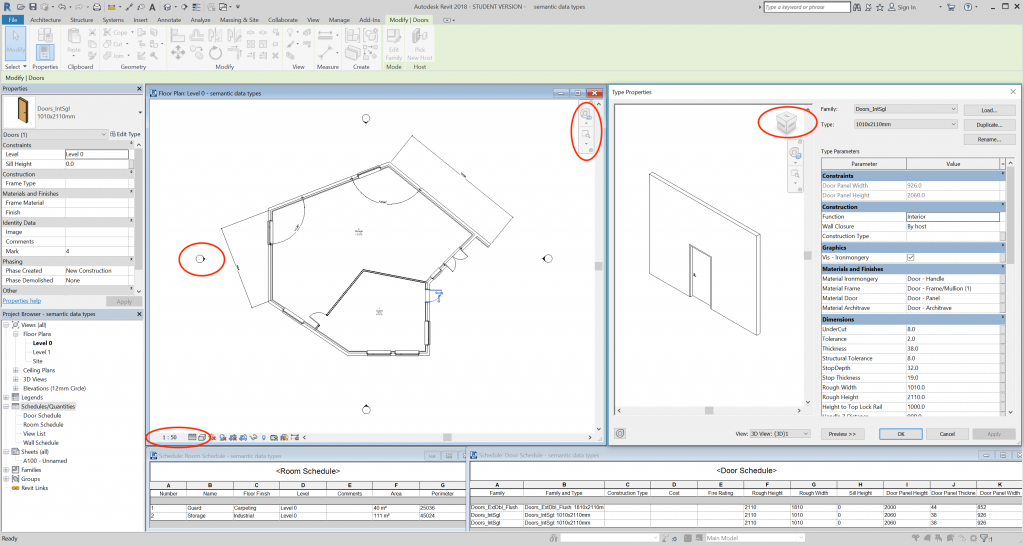
The presence of multiple windows on the screen also increases the number of visible metadata, such as window headers that describe the view in each window (Figure 14).
Anti-data remain difficult to distinguish from data missing due to abstraction or deferment. The lack of values for e.g. cost or fire rating for some building elements may merely indicate that their calculation has yet to take place, despite the availability of the necessary primary data. After all, both are calculated on the basis of materials present in the elements: if these materials are known, cost and fire ratings are easy to derive. One should remember this inherent duality in anti-data: they do not only indicate missing primary data but the presence of anti-data is significant and meaningful by itself. For example, not knowing the materials and finishes of a window frame, although the window symbol is quite detailed, signifies that the interfacing of the window to a wall is a non-trivial problem that remains to be solved. Interfacing typically produces anti-data, especially when sub-models meet in BIM, e.g. when the MEP and architectural sub-models are integrated, and the fastenings of pipes and cables to walls are present in neither. Anti-data generally necessitate action: no value (or “none”) for the demolition phase of an entity suggests that the entity has to be preserved during all demolition phases — not ignored but actively preserved with purposeful measures, which should be made explicit (Figure 15).
Information instances in BIM
Knowing the type of data in BIM is a prerequisite identifying information as it emerges in a model. The next step is to recognize it in the interfaces of the software. As described in the previous section, data are to be found in the symbols: their properties and relations. In the various views and windows of BIM software, one can easily find the properties of each symbol, either of the instance (Figure 16 & 18) or of the type (Figure 17). What one sees in most views and windows is a mix of different data types, with derivative data like a volume calculation or thermal resistance next to primary data, such as the length and thickness of a wall. Moreover, no view or window contains a comprehensive collection of properties. As a result, when a property changes in one view, the change is reflected in several other parts of the interface that accommodate the same property or data derived from it.
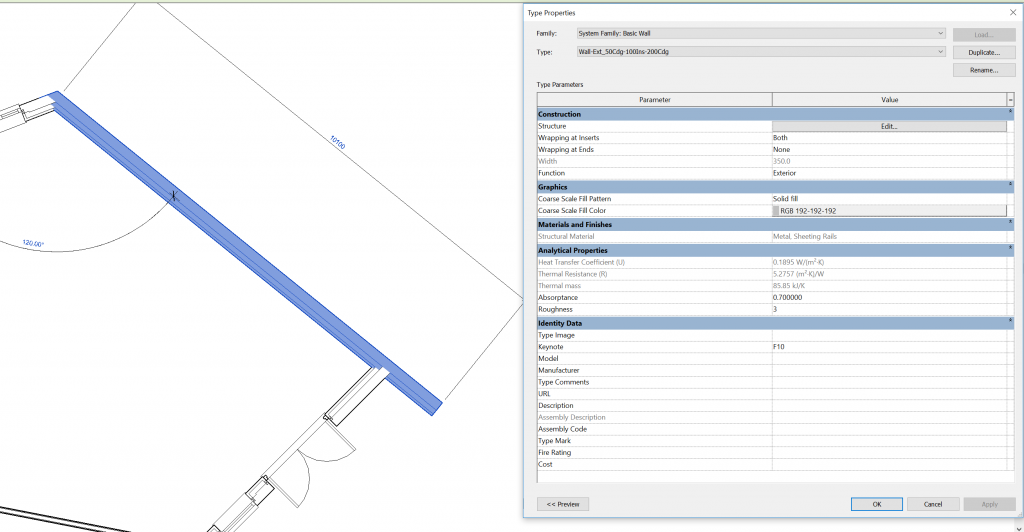
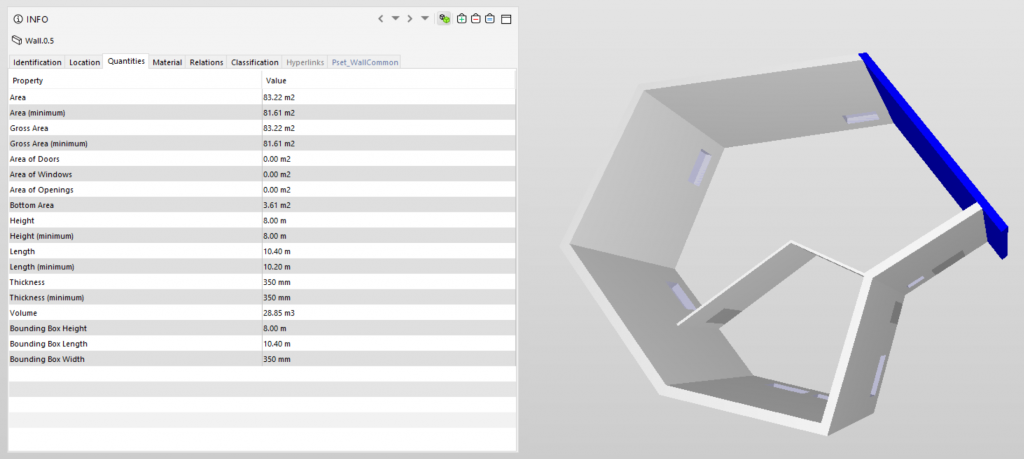
Any lack of uniformity in these properties, including the addition of new symbols to a model, qualifies as data. One can restrict the identification of data to each view separately but it makes more sense for IM to include all clones of the same property, in any view. Any derivative data that are automatically produced or modified as a result of the primary data changes count as different data instances. So, any change in the shape of a space counts as a single data instance, regardless of the view in which the user applies the change or of in how many views the change appears. The ensuing change in the space area value counts as a second instance of data; the change in the space volume as a third.
Relations between symbols are even more dispersed and often tacit. They can be found hidden in symbol behaviours (e.g. in that windows, doors or wash basins tend to stick to walls or in that walls tend to retain their co-termination), in explicit parametric rules and constraints, as well as in properties like construction time labels that determine incidental grouping. Discerning lacks of uniformity in relations is therefore often hard, especially because most derive variably from changes in the symbols. For example, modifying the length of a wall may inadvertently cause its co-termination with another wall to be removed or, if the co-termination is retained, to change the angle between the walls. Many relations can be made explicit and controllable through appropriate views like schedules. As we have seen, window and door schedules make explicit relations between openings and spaces. This extends to relations between properties of windows or doors and of the adjacent spaces, e.g. connects the fire rating of a door to whether a space on either side is part of a main fire egress route or the acoustic isolation offered by the door to the noise or privacy level of activities accommodated in either adjacent space.
Information instances can be categorized by the type of their data: primary, derivative, operational etc. Type is important for IM because it allows, firstly, to prioritize in terms of significance and, secondly, to link information to actors and stakeholders concerning authorship and custodianship. Primary information obviously carries a higher priority than derivative. Moreover, primary information (e.g. the shape of spaces) is produced or maintained by specific actors (e.g. designers), preferably with no interference by others who work with information derived from it (e.g. fire engineers). Information instances concerning space shape are passed on from the designers to the fire engineers, whose observations or recommendations are fed back to the designers, who then initiate possible further actions and produce new data. Understanding these flows, the information types they convey and transparently linking instances to each other and to actors or stakeholders is essential for IM.
Another categorization of information instances concerns scope. This leads to two fundamental categories:
- Instances comprising one or more properties or relations of a single symbol: the data are produced when one enters the symbol in the representation or when the symbol is modified, either interactively by a user or automatically, e.g. on the basis of a built-in behaviour, parametric rule etc. Instances of this category are basic and homogeneous: they refer to a single entity of a particular kind, e.g. a door. The entity can be:
- Generic in type, like an abstract internal door
- Contextually specific, such as a door for a particular wall in the design, i.e. partially defined by relations in the representation
- Specific in type, e.g. a specific model of a particular manufacturer, fixed in all its properties
- Instances comprising one or more properties or relations of multiple symbols, added or modified together, e.g. following a change of type for a number of internal walls, or a resizing of the building elements bounding a particular space. Consequently, instances of this category can be:
- Homogeneous, comprising symbols of the same type, e.g. all office spaces in a building
- Heterogeneous, comprising symbols of various types, usually related to each other in direct, contextual ways, e.g. the spaces and doors of a particular wing that make up a fire egress route
These categories account for all data and abstraction levels in a representation, from sub-symbols (like the modification of the geometry of a door handle in the definition of a door type) to changes in the height of a floor level that affects the location of all building elements and spaces on that floor, the size and composition of some (e.g. stairs) and potentially also relations to entities on adjacent floors. Understanding the scope of information is essential for IM: it determines the extent to which any information instance or change should be propagated to ensure consistency and coherence.
Symbols and their properties in context
So far we have considered the semantic data types of symbol properties in isolation, as if each symbol were a separate entity rather than incorporated in a representation. However, in the symbol graphs discussed in a previous chapter, we have seen that relations in a model profoundly affect the properties of each symbol. Parameterization adds to the number and complexity of such relations but even without parameterization there are many primary properties that become derivative in the context of a representation due to common, often implicit relations.
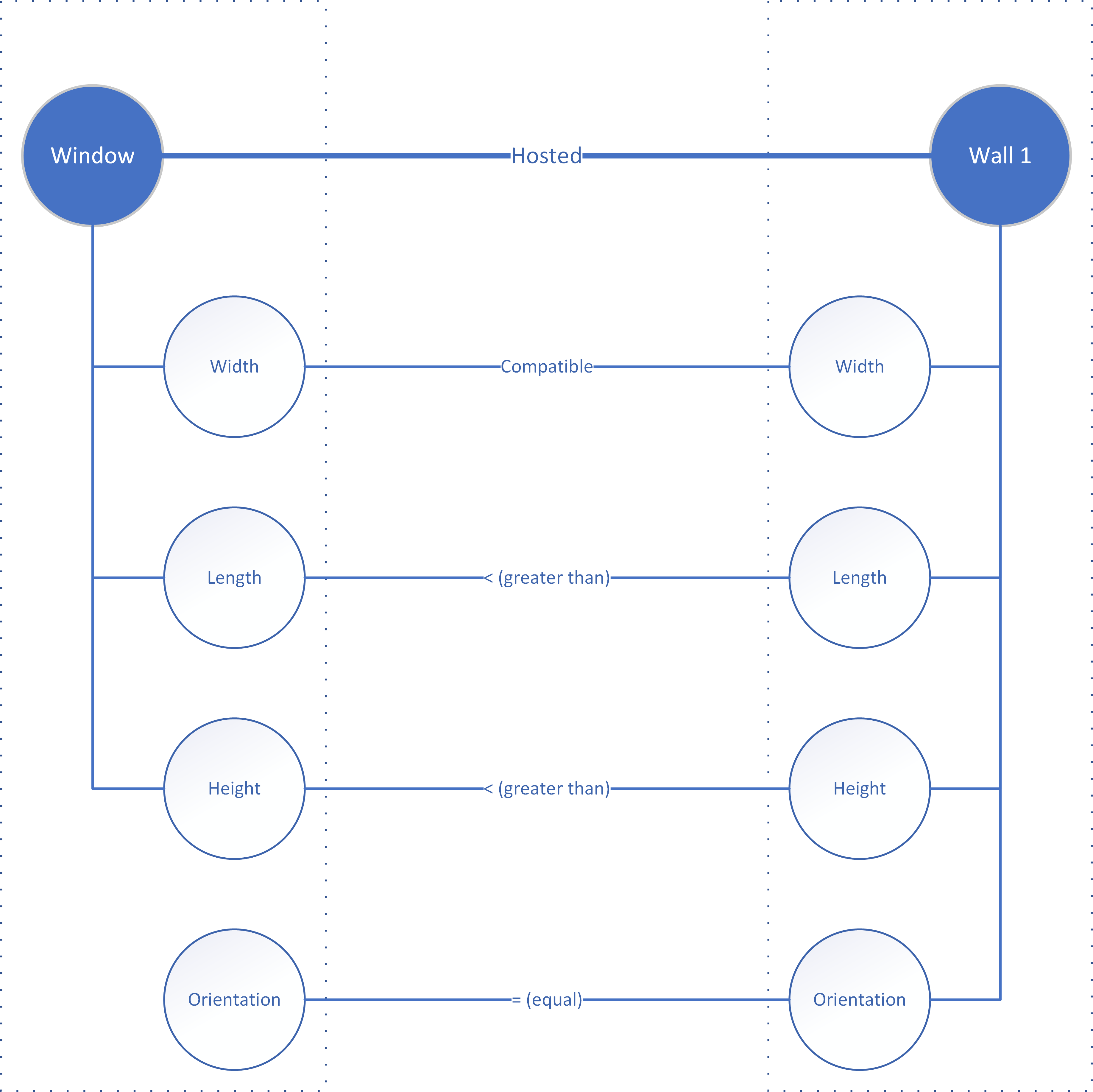
In the example of a window and the wall that hosts it, some properties of the window, such as orientation, are inherited from the corresponding properties of the hosting element (Figure 19). These relations therefore affect the semantic data type of symbol properties. Both the window and the wall in this example are each represented by a discrete symbol with its own properties. Most of these properties are primary data, i.e. essential for the identity of each symbol: length, height, width, material composition etc. BIM software routinely also adds properties that are derivative, i.e. products of functions on primary properties, such as area and volume but also fire rating and cost. Orientation is another derivative property that in a straight wall can be calculated from the relative position of the endpoints of the wall axis. This calculation applies to the wall but is not required for the window, which by definition inherits orientation from the wall, as does any other hosted element. One could argue that other properties of the window, notably its dimensions, remain primary in spite of the hosting relation but the fact that their values must be in a range determined by the wall properties also makes them derivative, only not in the strict sense of equality that applies to orientation. They remain the same as in the unattached window so long as they do not cause any interfacing problems with the wall but, when this happens, it becomes clear that the width of the window is linked to that of the hosting wall.
Similar derivation of dimensions on the basis of relations also applies to non-hosted elements. For example, the height of a wall is normally constrained by the position of the floor above and the floor underneath the wall: the wall height is derived from difference in vertical level between the two floors that bound it (Figure 20).
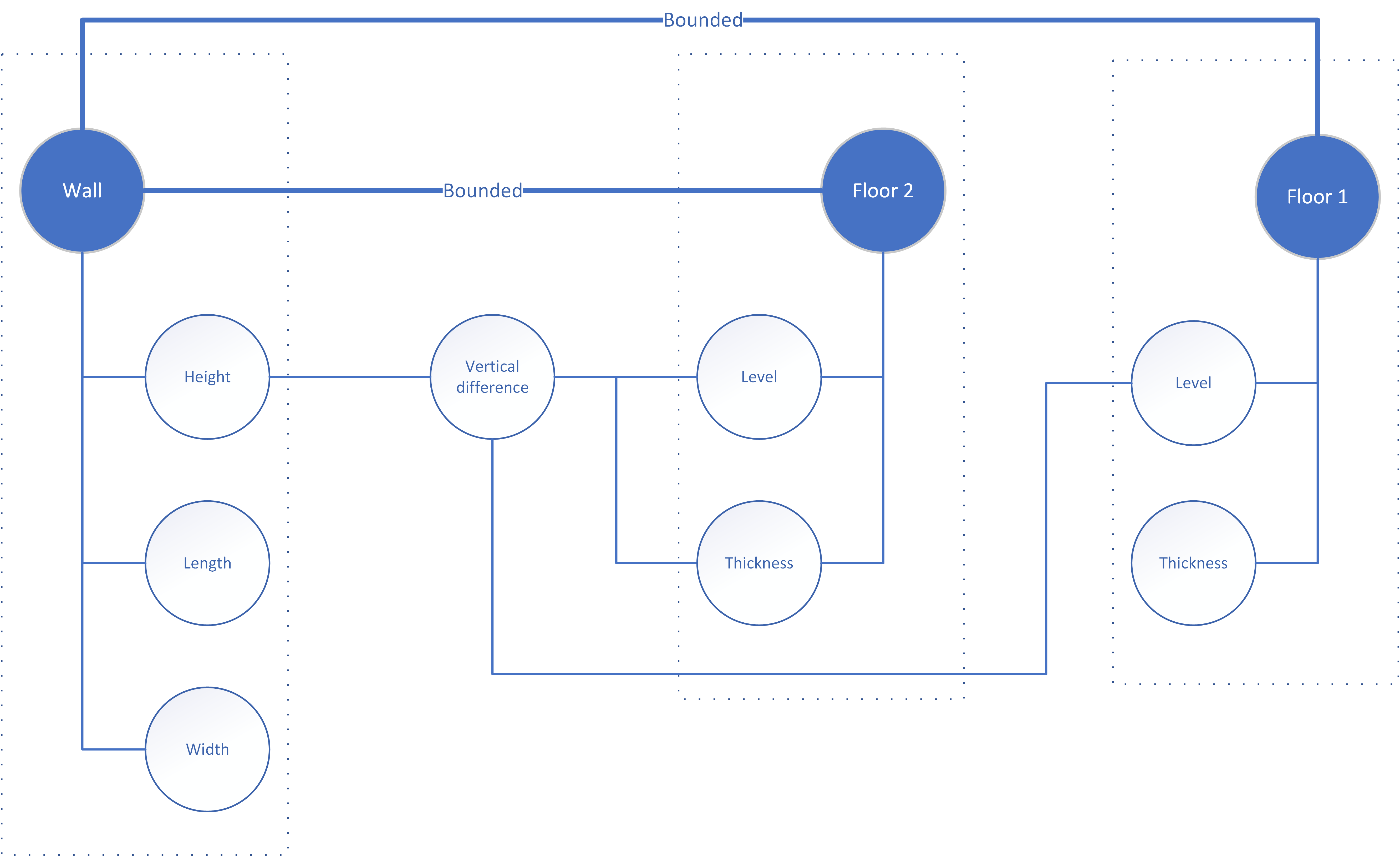
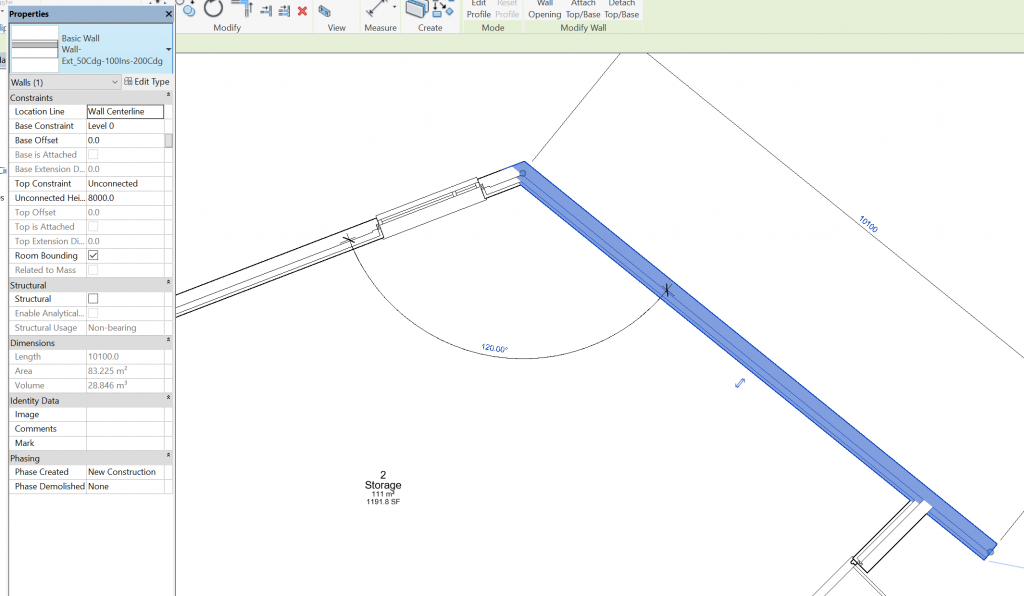
This relation seems straightforward but BIM software makes it more complicated in a way that reveals the intricate chain behind any relation we isolate by way of example. A wall in BIM may be constrained not by floor symbols but by levels: reference planes in the model setup. The wall in Figure 21 has its base on Level 1 (which also determines the position of a floor symbol) but its top is determined by a default value of the type, as indicated in the properties palette. The wall appears to connect to the floor underneath it but in fact the position of both is determined by the same level.
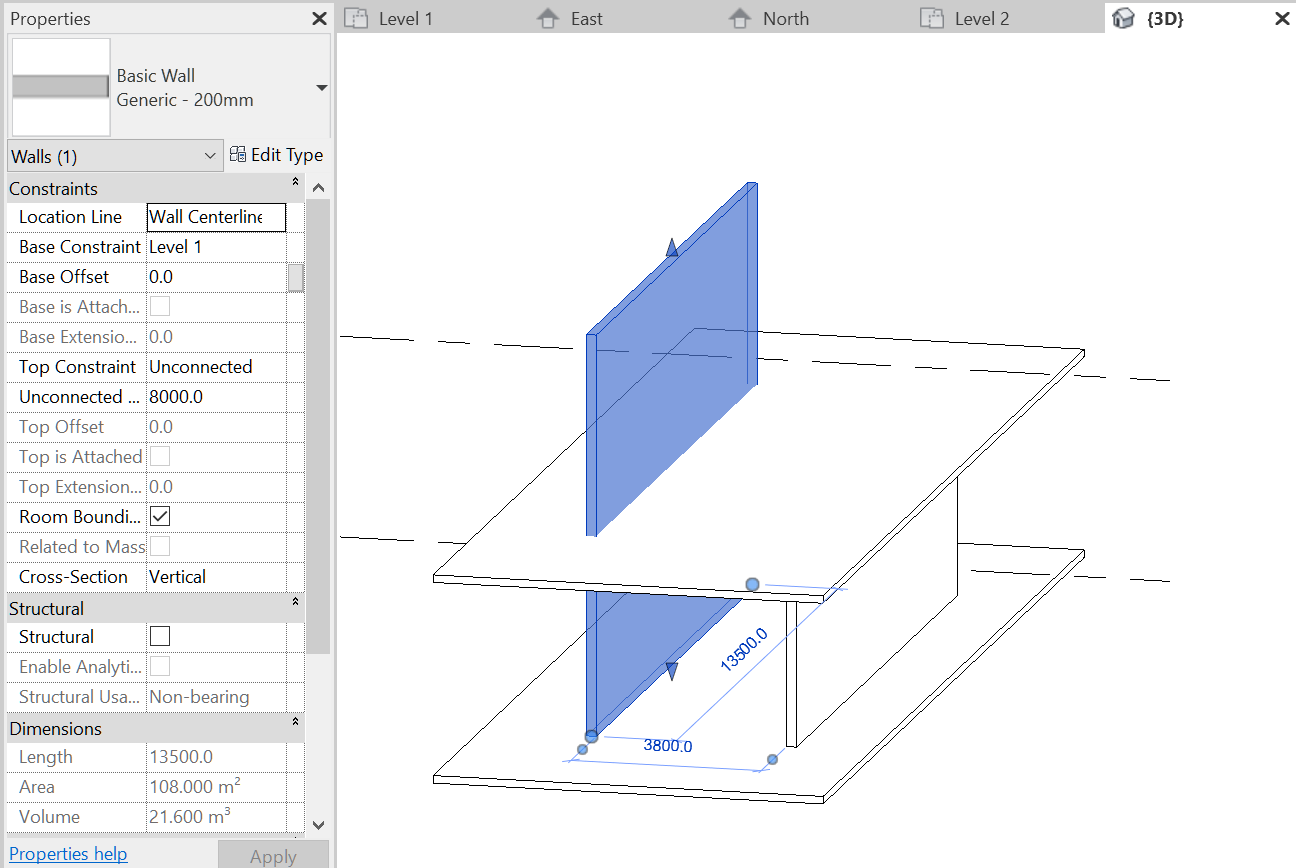
On the other hand, the top of the wall in Figure 22 is determined by Level 2, which also constrains the position of another floor symbol. As the properties palette reveals, this wall is moreover attached at the top. This means that if the floor above the wall is moved to another height, the wall tries to remain connected to it. If the floor below is moved, the wall sticks to the level, losing contact with the floor. If the base was also attached, then the wall would be fully constrained, as in Figure 20.
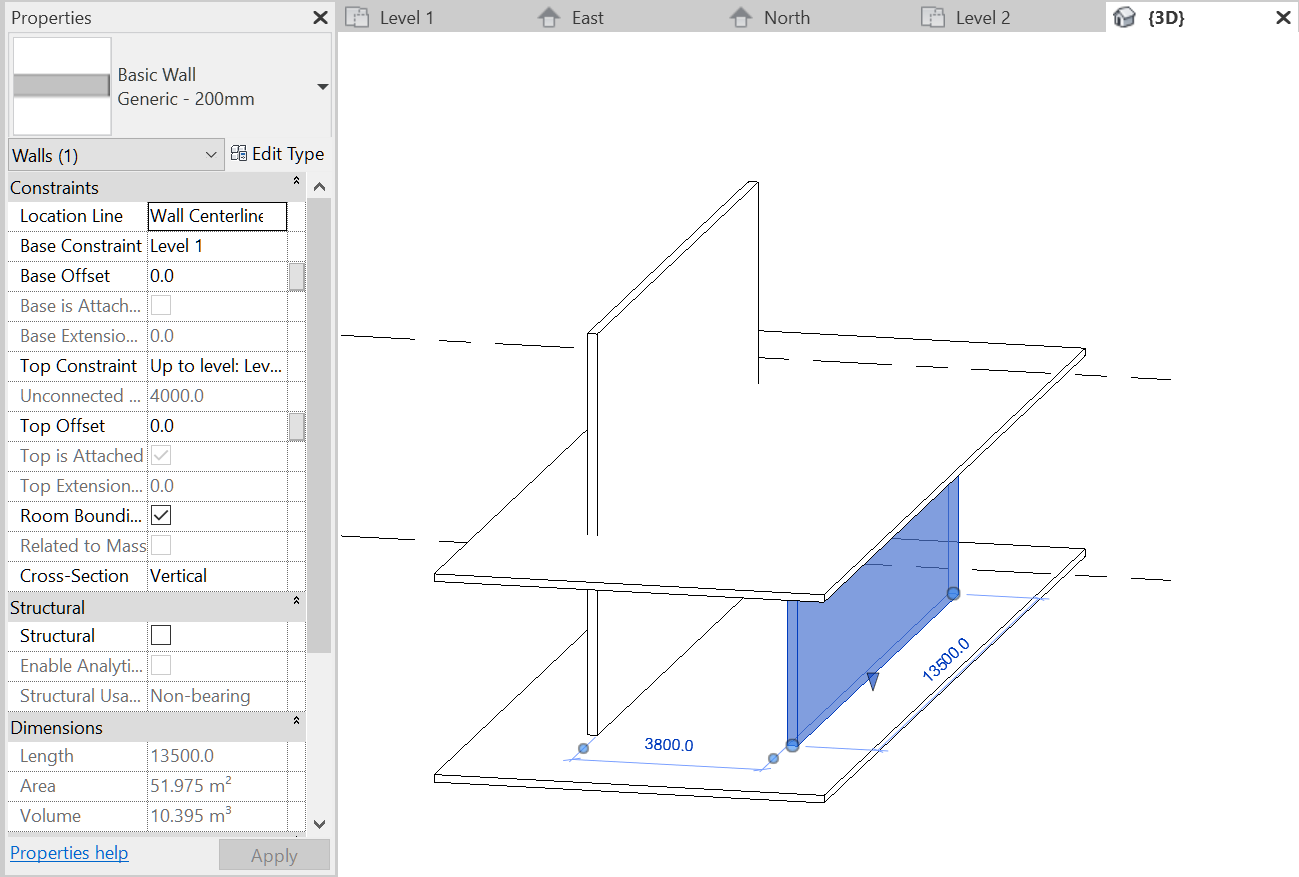
The above examples demonstrate that the semantic type of each property is often affected by constraints external to the symbols. The width of a wall, for instance, can be determined by its composition out of various layers of different materials, each with its own thickness. This makes wall width derivative and creates some dimensional and technical tolerances, as e.g. a wall can be made thinner by replacing an insulation layer with thinner, better material, without changing the wall’s thermal performance. On the other hand, wall width can also be fixed by external constraints, e.g. for reasons of standardization. This makes wall width primary, while the material composition of the wall (the material layers and their thickness) becomes derivative from the fixed wall width and requirements on e.g. thermal or acoustic performance.
Some of the most important external constraints come from planning regulations. These often determine large parts of a design, e.g. the position of external walls by a setback from the plot boundaries. This means that the footprint of the building is derived from the plot shape and dimensions minus the setbacks. Similarly, most Dutch planning regulations impose a setback from the ends of the roof for dormer windows, e.g. 100 cm from the bottom and side ends, and 50 cm from the top (Figure 23). Consequently, the dimensions of the dormer are derived from those of the roof, which in turn derive from the building footprint, and external constraints, including on the roof pitch (also determined by planning regulations, either by a fixed value, such as 30 degrees, or a bandwidth, e.g. 25–40 degrees). In short, a building representation is based on such networks of relations and constraints, making many primary properties dependent on others and therefore derivative.
The conclusions that can be drawn from the above are:
- The semantic type is sensitive to the context: what in an isolated symbol is a primary property may become derivative in a representation where the symbol connects to others.
- These others include symbols in the same representation, as well as external information entities, such as constraints from standards or planning regulations. For IM purposes, these too should be explicitly included in the representation.
Key Takeaways
- A information instance consists of one or more data which are well-formed and meaningful
- Data are lacks of uniformity in what we perceive at a given moment or between different states of a percept or between two symbols in a percept
- Data can be primary, anti-data, derivative, operational or metadata
- There are significant differences between analogue and digital building representations concerning data types, with symbols like dimension lines being primary in the one and derivative in the other
- In BIM, lacks of uniformity can be identified in the properties and relations of symbols
- Information instances can be categorized by the semantic type of their data and by their scope in the representation
- Semantic type depends on the context, which may turn primary data into derivative
Exercises
- Identify the semantic data types in the infobox of a Wikipedia biographic lemma (the summary panel on the top right), e.g. https://en.Wikipedia.org/wiki/Aldo_van_Eyck (Figure 19),[6] and in the basic page information of the same lemma (e.g. https://en.Wikipedia.org/w/index.php?title=Aldo_van_Eyck&action=info)
- Explain the information instances produced in BIM when one inserts a door in an existing wall. Use the following notation:
(scope; symbol; name of property or relation; value of property or relation; time; semantic data type)
If the instances concern multiple symbols, use the notation to describe each symbol separately. - Explain the information instances produced in BIM when one moves an existing door to a slightly different position in an existing wall. Use the above notation for each concerned symbol separately.
- In BIM it is claimed that one can add information dimensions to the three geometric dimensions, turning 3D into nD: 4D comes with the addition of time (e.g. when the symbolized entity is constructed), 5D with the addition of cost, 6D with sustainability, 7D with facility management, 8D with accident prevention (or safety) etc. However, for something to qualify as a dimension, it should be primary and not derivative, otherwise area and volume would be dimensions, too.[7]
Describe how the values of these four dimensions emerge and change throughout the lifecycle of a building element or component, such as a door, window, floor, ceiling etc., and which primary or derivative information attracts attention in various stages and activities after development (procurement, transport, realization, maintenance, refurbishment, renovation, demolition etc.). Present your results in a table. - IFC (Industry Foundation Classes) is a standard underlying BIM, in particular concerning how each entity is represented. Identify the semantic data types in the IFC wall base quantities, i.e. quantities that are common to the definition of all occurrences of walls (http://www.buildingsmart.org/ifc/dev/IFC4_3/RC2/html/schema/ifcsharedbldgelements/qset/qto_wallbasequantities.htm). Pay particular attention to derivative quantities present in the specification. If each of the quantities becomes a symbol property in BIM, calculate how much of a typical model consists of derivative data, both in percentage and megabytes (assuming that what holds for walls also holds for all entities in BIM).

- Zins, C., 2007. Conceptual approaches for defining data, information, and knowledge. Journal of the American Society for Information Science and Technology. 58(4) 479-493 DOI: 10.1002/asi.20508 ↵
- There are several fundamental sources on the MTC, starting with the original publication: Shannon, C., 1948. A mathematical theory of communication. Bell System Technical Journal, 27(July, October), 379-423, 623-656; Shannon, C.E., & Weaver, W., 1998. The mathematical theory of communication. Urbana IL: University of Illinois Press; Cover, T.M., & Thomas, J.A., 2006. Elements of information theory (2nd ed.). Hoboken NJ: Wiley-Interscience; Pierce, J.R., 1980. An introduction to information theory: symbols, signals & noise (2nd, rev. ed.). New York: Dover. ↵
- The classification of theories of information is after: Sommaruga, G., 2009. Introduction. G. Sommaruga (ed), Formal Theories of Information: From Shannon to semantic information theory and general concepts of information. Berlin, Heidelberg: Springer. ↵
- Floridi’s theory has been published in: Floridi, L., 2008. Trends in the philosophy of information. P. Adriaans & J. v. Benthem (eds), Philosophy of information. Amsterdam: North-Holland; Floridi, L., 2009. Philosophical conceptions of information. G. Sommaruga (ed), Formal Theories of Information: From Shannon to semantic information theory and general concepts of information. Berlin, Heidelberg: Springer; Floridi, L., 2016. Semantic conceptions of information. The Stanford Encyclopedia of Philosophy. https://plato.stanford.edu/entries/information-semantic/ ↵
- In later publications Floridi has used the term secondary data instead of anti-data but the new name seems rather confusing, suggesting data of a lesser importance rather than the converse of primary data. ↵
- Source: https://en.Wikipedia.org/wiki/Aldo_van_Eyck; photograph credit: Aldo van Eyck in 1970 by Bert Verhoef, licensed under CC BY-SA 3.0 NL ↵
- Koutamanis, A., 2020. Dimensionality in BIM: Why BIM cannot have more than four dimensions? Automation in Construction, 114, 2020, 103153, https://doi.org/10.1016/j.autcon.2020.103153. ↵